Что такое квантизация — почему большая модель влезает в обычную видеокарту
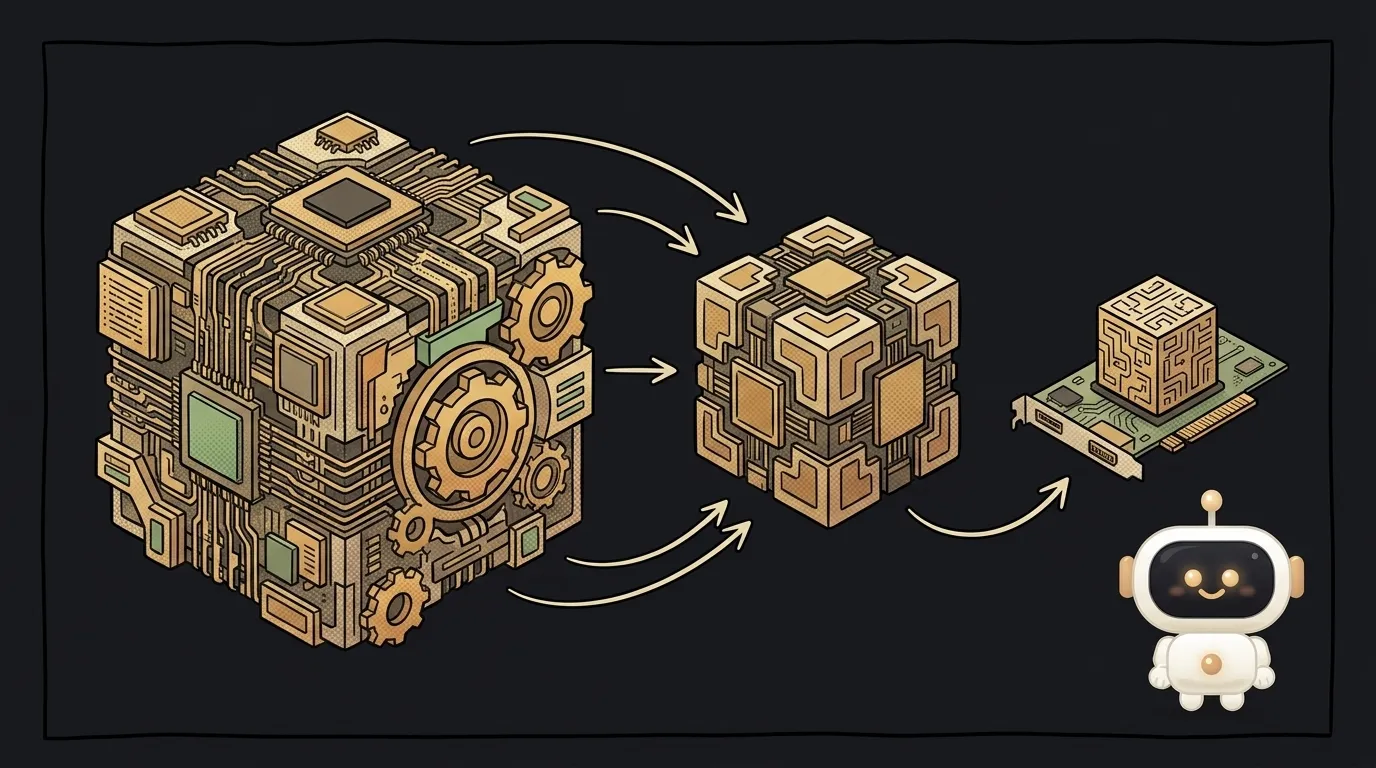
Смотри, ты наверняка встречал такое: «эта модель на 27 миллиардов параметров, но в сжатом виде влезает в 18 ГБ видеопамяти». И думаешь: как такая громадина помещается на домашнюю карту? Ответ — квантизация.
Из чего состоит модель
Модель — это, по сути, гигантская куча чисел (их называют веса). Миллиарды чисел, которые она подкручивала во время обучения. Когда модель «думает», она перемножает эти числа.
Обычно каждое число хранится точно — на него отводят 16 бит памяти. Миллиарды точных чисел = десятки гигабайт. Вот почему «большие» модели тяжёлые.
Что делает квантизация
Квантизация — это огрубление чисел. Вместо точных 16 бит на число берут 8 бит, а то и 4. Числа становятся «грубее», но их в разы меньше по памяти:
- 16 бит → 8 бит — модель вдвое легче;
- 16 бит → 4 бита — вчетверо легче.
Аналогия — фотография. Снимок в полном разрешении весит много. Сожми его — на глаз почти не отличишь, а весит в разы меньше. С моделью так же: огрубили числа — она похудела, а отвечает почти так же.
Чем за это платишь
Немного качеством. Чем сильнее жмёшь (4 бита и ниже), тем заметнее модель начинает ошибаться. Но золотая середина (обычно 4–8 бит) теряет так мало, что для большинства задач разницы не видно — зато модель запускается там, где раньше не помещалась.
Что тебе с этого
Квантизация — причина, по которой ты можешь гонять серьёзные модели локально: на своей видеокарте, бесплатно и приватно, без облака. Когда выбираешь модель для локального запуска, ты увидишь пометки вроде Q4, Q8, 4-bit — это и есть степень сжатия. Бери версию, которая влезает в твою память, и пробуй.
Без магии: квантизация не делает модель умнее — она просто ужимает её, чтобы влезла к тебе. Маленькая потеря качества в обмен на «работает на моём ноуте».
Читайте дальше

Почему мой промпт не работает — 3 причины и как починить каждую

Что такое мультимодальность — как ИИ «видит» картинку, хотя у него нет глаз

Что такое дообучение модели — и почему оно почти не учит её фактам

Что такое открытые веса — и почему это не то же самое, что open source

Агент, который следит за вебом сам — и пишет первым, когда появилось то, что ты ждёшь
