What is a mixture of experts (MoE) — why a model is huge yet fast
Look at the contradiction: a model can have 600+ billion parameters, yet it answers fast and costs little. How? Huge usually means slow.
The secret is that the model doesn't switch all of itself on for every word. Only a small piece fires. This trick is called a mixture of experts, or MoE — and we'll unpack how it works.
Mixture of experts in one sentence
MoE is a model built from many small "experts," but only a few of them work on each chunk of text.
Picture a big hospital. There are hundreds of doctors, but not every one examines you. The front desk looks at your problem and sends you to the two right specialists. The rest are busy with others.
MoE works the same way. Inside are dozens of experts. For each word, not all of them switch on — only the fitting ones.
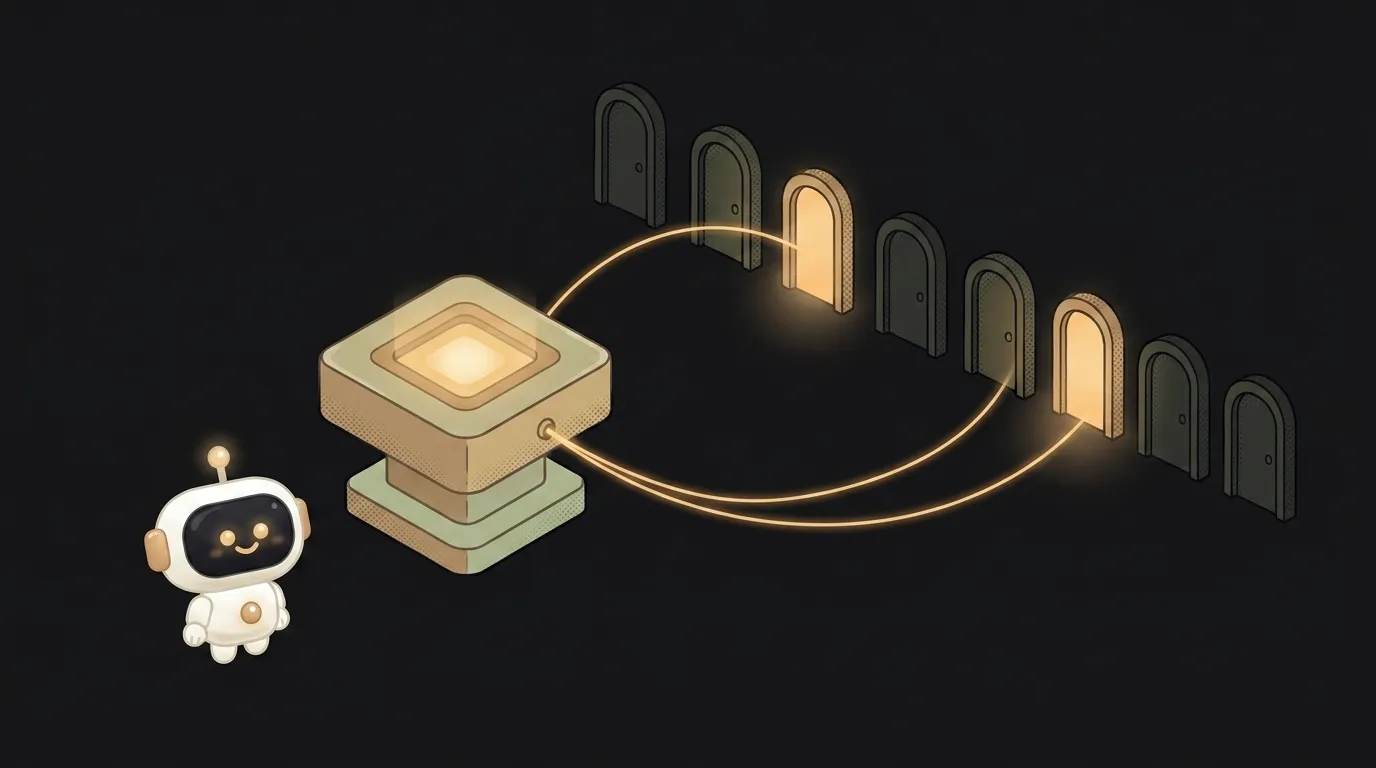
How the router picks experts
The key piece is a tiny "router" (also called gating). That's the front desk.
For each token, the router quickly decides: which experts are useful here? It switches on, say, two out of eight. The other six sleep on this word and burn no electricity.
On the next word the choice can change. One expert is better at code, another at a language, a third at math. The router hands work to whoever is strongest on the current chunk.
You get a team of specialists instead of one "generalist doctor" trying to know everything at once.
The point: huge but fast
Here's the win. The model's size sets how much it knows in total. Its speed and price depend on how many parameters actually fire per word.
In a normal (dense) model, every parameter works on every word. In MoE, only the active ones — a small fraction.
- DeepSeek-V3: about 671 billion parameters total, but only ~37 billion active per token.
- Mistral's Mixtral 8×7B: eight experts, two switched on per word.
The result: knowledge like a giant's, but the inference bill and speed of a model many times smaller. That's why MoE is almost everywhere in flagships now.
Where you'll see it
"MoE" will pop up in model descriptions and names. And two numbers beside it that used to confuse people:
- "total parameters" — the overall size, how much the model weighs and knows;
- "active parameters" — how many work per word, which drives speed and price.
When you see "671B total / 37B active" — now you know it's not a typo. That's the essence of MoE: a big warehouse of knowledge, a small crew working at a time.
Is an MoE model smarter than a normal one?
Not automatically. For the same training budget, MoE is often more efficient: more knowledge at the same speed. But "smarter" depends on the data, training, and transformer architecture, not on the MoE label alone. It's a way to save, not a magic smartness button.
Does "8x7B" mean 56 billion?
Not quite. "8×7B" is eight experts of roughly 7 billion each, but they share common parts. So the total comes out lower (Mixtral is ~47B), and only about 13B is active per word. Count by active parameters if you want to gauge speed.
Short story-lessons, an agent simulator and daily practice — in our mobile app. Free.
Read next

What is model distillation — how a big AI teaches a small one

What is a knowledge cutoff — and why the model lies about yesterday

REST or GraphQL — which to pick as a beginner, and why

What is a reasoning model — and why you pay for thoughts you never see

What is a diffusion model — why AI images are born from noise
